第七章:Agentic Research 方法论
引言:超越观察与回测,进入”可创造”的经济学宇宙
科学的进步史,本质上是其研究工具的进化史。从伽利略的望远镜让人类得以窥见天体运行的秩序,到大型强子对撞机让我们能够在受控环境中重现宇宙大爆炸的瞬间,每一次工具的飞跃都开启了一个全新的认知维度。在经济学领域,我们的”望远镜”是计量经济学,它通过分析历史数据来寻找相关性;我们的”实验室”是行为经济学实验,它在高度简化的环境中观察人类的有限理性。这些工具在过去一个世纪里为我们带来了深刻的洞见,但面对一个由数万亿个高速、自主、相互作用的智能体构成的经济未来,它们正显得力不从心。
历史数据无法预测一个由全新物种主导的经济体的涌现行为;实验室环境无法模拟数百万智能体互联产生的复杂网络效应;理论模型中的理性人假设在算法驱动的世界中更是捉襟见肘。我们需要一场方法论的革命。我们需要的,是经济学领域的”大型强子对撞机”——一个能够让我们不仅能”观察”,更能”创造”和”复现”复杂经济现象的实验平台。
Agentic Research 正是为此而生的全新科学范式。它的核心论断是:研究智能体经济的最佳、甚至唯一的方式,就是用智能体本身作为研究工具。 我们将构建一个大规模、高保真、可审计的数字孪生实验场(Testbed),在这个实验场中,由AI驱动的研究智能体(Research Agents)自主地提出假说、设计实验、执行模拟、分析结果、进行同行评议,并最终将可信的知识固化为不可篡改的记录。
本章将系统性地阐述这一方法论的全部内涵。我们将从其哲学基础出发,定义其区别于传统科学的核心原则;我们将详细介绍构成这一研究体系的”智能体科研管弦乐队”的各个角色;我们将描绘一个从提出问题到发布成果的完整、闭环的研究生命周期;最后,我们将阐明支撑这一切的技术基础设施,包括实验场、SDK和作为激励核心的 ARC 代币。这不仅是一个研究工具的介绍,更是一份关于未来知识如何被创造、验证和拥有的宣言。
7.1 认识论的飞跃:Agentic Research 的四大支柱
在深入技术细节之前,我们必须首先理解 Agentic Research 在科学哲学层面所带来的根本性转变。它建立在四大认识论支柱之上,这些支柱共同定义了其与传统研究范式的区别。
7.1.1 支柱一:激进的可复现性 (Radical Reproducibility)
传统困境: “可复现性危机”(Replication Crisis)是当代社会科学乃至众多硬科学领域共同面临的巨大挑战。研究结果难以被独立第三方复现,其原因多种多样:数据不公开、实验代码丢失、实验条件描述不清、微妙的”研究者效应”等。这严重侵蚀了科学知识的可信度。
Agentic Research 的解决方案: 我们将可复现性从一个”良好实践”提升为一个”强制性架构属性”。
-
一切皆可审计: 每一个 Agentic Research 实验的所有要素——包括其初始条件、环境参数、所有参与智能体的源代码(或其哈希)、每一笔交互记录、产生的全部原始数据——都被记录在一个由内容寻址的、不可篡改的存储网络(如 IPFS 或 Arweave)上
-
一键复现: 任何研究者都可以获取这个完整的”实验快照”,并在本地或云端一键启动一个完全相同的实验副本。结果的复现不再依赖于模糊的文字描述,而是变成了确定性的代码执行
-
“无证明,无知识” (No Proof, No Knowledge): 在这个范式下,一个没有附带其完整、可执行的实验快照的研究成果,将被视为一个”未经证实的宣称”,而非一个可信的科学知识。这将从根本上终结经济学研究中”黑箱模型”和”私有数据”的时代
7.1.2 支柱二:计算经验主义 (Computational Empiricism)
传统范式: 传统经济学研究在很大程度上是”向后看”的。计量经济学通过复杂的统计模型拟合历史数据,试图从中发现因果关系。这种方法的有效性,完全取决于”未来会像过去一样”这一核心假设。对于一个充斥着前所未有的技术和行为模式的智能体经济,这一假设是极其脆弱的。
Agentic Research 的解决方案: 我们提倡一种”向前看”的、基于生成和创造的经验主义。
-
从”拟合数据”到”生成数据”: 研究的核心不再是从存量数据中挖掘模式,而是通过构建一个理论上合理的微观世界(定义智能体的行为规则和环境),然后运行这个世界,让数百万次交互生成全新的、涌现的宏观数据
-
理论即代码 (Theory as Code): 经济学家的理论不再仅仅是一组数学方程和文字描述,而是一个可执行的、参数化的计算机程序。一个关于”智能体风险偏好如何影响市场波动性”的理论,将被实现为一个可以调整
risk_aversion参数的智能体策略代码 -
实验即检验: 理论的有效性,不再通过其对历史数据的拟合优度(R-squared)来判断,而是通过其生成的模拟世界与某些可观测的宏观指标(或另一个理论生成的模拟世界)的相似度来检验。科学的进步变成了构建更具预测力和解释力的”模拟宇宙”的竞赛
7.1.3 支柱三:涌现为中心 (Emergence as a First-class Citizen)
传统挑战: 复杂系统科学告诉我们,”整体大于部分之和”。宏观层面的现象(如市场崩盘、交通拥堵)往往是微观个体简单交互规则所”涌现”(Emerge)出的、难以从个体行为直接预测的集体行为。传统经济学的微观基础分析(研究单个理性人)和宏观总量分析(研究 GDP、通胀等)之间,长期存在着一条鸿沟。
Agentic Research 的解决方案: 我们的方法论将研究涌现现象作为其核心目标。
-
大规模代理人基模型 (Large-Scale Agent-based Modeling, ABM): Agentic Research 的实验场本质上是一个超大规模的 ABM 平台。它允许研究者同时模拟数百万个异构智能体的交互,并观察在不同规则下会涌现出怎样的宏观结构
-
寻找”相变”: 研究的重点是寻找系统的”相变临界点”。例如,当网络中”耐心”智能体的比例低于某个阈值时,整个市场的交易秩序是否会突然从稳定状态崩溃为高频振荡状态?当信息传播速度超过某个临界值时,是否会更容易产生非理性的”信息瀑布”?
-
因果干预: 通过在模拟中精确地”敲除”或”修改”某一部分智能体的行为或规则,我们可以清晰地观察这种微观干预对宏观涌现现象的因果影响,这是在真实世界中几乎不可能实现的
7.1.4 支柱四:自反式改进 (Self-Reflexive Improvement)
传统模式: 科学知识的增长是一个开放的、线性的过程。一个研究的结论可能在数年后才被另一个研究所修正。
Agentic Research 的解决方案: 我们构建了一个自引用的、递归的知识增长闭环。
-
用研究成果改进研究工具: 通过 Agentic Research 发现的、关于”如何设计更有效的激励机制”的知识,可以被立即用来改进实验场本身(例如,优化 ARC 代币的分配算法)
-
智能体学习如何做研究: 我们可以训练一个”元学习智能体”(Meta-learning Agent),其目标是发现更高效的实验设计或数据分析方法。它通过观察大量历史上的成功和失败的研究项目,来学习”科学发现的模式”
-
自我进化的经济理论: 整个 Agentic Research 平台本身,可以被视为一个巨大的”理论进化智能体”。它的”基因”是各种经济理论模型(代码),它的”环境”是现实世界的数据流,它的”适应度”是其模拟结果的预测准确性。通过不断的”变异”(提出新理论)和”选择”(用数据检验),这个系统能够实现经济学知识的加速进化
这四大支柱共同将 Agentic Research 定义为一种全新的科学实践:它可信、可计算、面向未来、并以理解复杂系统的涌现行为为核心。
7.2 智能体科研管弦乐队:Agentic Research 中的核心角色
要实现如此宏大的研究范式,单靠人类研究者是不够的。我们需要一支由高度专业化的 AI 智能体组成的”科研管弦乐队”,在人类指挥家(首席研究员)的引导下,协同演奏出知识发现的华美乐章。以下是这个乐队中的核心成员。
7.2.1 数据考古学家 (Data Archaeologist Agent)
角色隐喻: 信息世界的”印第安纳·琼斯”,负责发掘和整理知识的原材料。
核心功能:
-
全网数据爬取: 根据研究课题,自主地从公共区块链、API、学术论文库(如 arXiv)、代码仓库(如 GitHub)、新闻网站等来源抓取相关数据
-
数据清洗与结构化: 处理非结构化文本、解析表格、标准化数据格式,将混杂的信息源转化为干净、可用的数据集
-
可信溯源标记: 为每一条数据都打上其原始来源的元数据标签和时间戳,确保其可追溯性,为激进的可复现性奠定基础
技术实现: 基于先进的网页抓取框架(如 Scrapy、Beautiful Soup),并结合自然语言处理(NLP)模型进行实体识别、关系提取和数据标准化。
7.2.2 假说吟游诗人 (Hypothesis Bard Agent)
角色隐喻: 思想的”催化剂”和”灵感来源”,负责在已有的知识海洋中提出新颖、可检验的科学问题。
核心功能:
-
文献综述与知识图谱构建: 消化”数据考古学家”提供的海量文献,构建一个关于特定领域(如”拍卖理论”)的动态知识图谱
-
寻找”知识缺口”: 通过分析知识图谱的结构,识别出那些被研究较少的、存在矛盾结论的、或是有待探索的”无人区”
-
生成可检验假说: 基于发现的知识缺口,利用大型语言模型(LLM)的创造性推理能力,生成一系列形式化的、可被实验检验的假说。例如:”在一个信息有延迟的市场中,采用 ZK-Rollup 的结算层相比 Optimistic Rollup,是否会显著降低市场的极端波动性?”
技术实现: 以 GPT-4、Claude 3 等顶级 LLM 为核心,通过精巧的提示工程(Prompt Engineering)和思维链(Chain-of-Thought)推理,引导其进行创造性的科学思考。
7.2.3 实验建筑师 (Experiment Architect Agent)
角色隐喻: 科学实验的”蓝图设计师”,负责将抽象的假说转化为具体的、可执行的实验方案。
核心功能:
-
参数空间定义: 与人类研究员协作,将假说中的变量(如”信息延迟”、”结算层类型”)映射为实验场中可调控的参数
-
智能体策略设计: 为实验设计所需的参与者(如”高频交易者”、”长线投资者”、”做市商”)编写或选择合适的决策策略
π代码 -
度量指标(Metrics)选择: 定义用于评估实验结果的关键性能指标(KPIs),例如:市场流动性、价格波动率、交易成功率、网络总 A-FCF 等
-
生成实验配置代码: 将上述所有设计,自动编译成一份标准化的、可被实验场直接读取和执行的配置文件(如 YAML 或 JSON 格式)
技术实现: 结合了专家系统(用于编码实验设计的最佳实践)和代码生成模型,能够将高级的实验意图翻译成低级的机器指令。
7.2.4 世界模拟器 (World Simulator Engine)
角色隐喻: 实验场的”物理引擎”,负责忠实地执行实验方案,让虚拟世界运转起来。
核心功能:
-
环境实例化: 根据”实验建筑师”提供的配置文件,在沙箱环境中创建网络拓扑、实例化数百万个智能体、并设置初始条件
-
离散时间步进: 以确定性的、可控的离散时间步(Ticks)来驱动整个模拟的进行。在每个时间步,所有智能体根据其策略
π和观察到的状态s_t做出行动a_t -
交互与状态更新: 计算所有行动的后果,更新全局状态(如市场价格、网络拥堵情况)和每个智能体的内部状态
-
全量数据记录: 将每个时间步发生的每一个事件、每一个状态变化,都以不可篡改的方式记录下来
技术实现: 这是整个系统的核心引擎,通常基于高性能的离散事件模拟框架(如 Mesa, NetLogo 的大规模并行版本)构建,并深度集成了区块链或 DLT 组件以确保数据的完整性。
7.2.5 涌现分析师 (Emergence Analyst Agent)
角色隐喻: 数据的”解梦师”,负责从模拟产生的海量数据中,发现隐藏的宏观模式和涌现规律。
核心功能:
-
时间序列分析: 分析宏观指标(如价格、波动率)的时间序列数据,寻找趋势、周期和突变点
-
网络分析: 将智能体的交互关系建模为动态网络,分析其拓扑结构、中心节点、社群演化等
-
模式识别与聚类: 使用无监督学习算法(如 K-Means, DBSCAN)对智能体的行为进行聚类,发现不同的”行为物种”及其演化路径
-
因果推断: 通过比较不同实验组(对照组与干预组)的结果,量化特定微观规则变化对宏观涌现现象的因果效应
技术实现: 一个强大的数据科学和机器学习工具箱,包含从传统的统计方法到深度学习(如用于时间序列预测的 LSTM)和拓扑数据分析(TDA)等前沿技术。
7.2.6 哲学辩论家 (Philosophical Adversary Agent)
角色隐喻: 科学进步的”磨刀石”,永远的”反对派”,负责挑战和攻击当前的研究结论,以增强其鲁棒性。
核心功能:
-
寻找反例: 主动搜索实验的参数空间,试图找到能够推翻当前假说或结论的”黑天鹅”场景
-
生成对抗性攻击: 设计特殊的智能体策略,专门用来利用和攻击当前系统中的潜在漏洞或不合理规则。例如,设计一个能通过协同操纵来”欺骗”ANI 激励机制的智能体群体
-
鲁棒性测试: 通过向模拟中注入各种噪声、随机冲击和极端事件(如部分网络瘫痪、关键节点失联),来测试一个理论或机制在非理想条件下的表现
技术实现: 大量使用生成对抗网络(GANs)、强化学习中的对抗性策略以及混沌工程(Chaos Engineering)的思想。
7.2.7 去中心化同行评议网络 (Decentralized Peer Review Network)
角色隐喻: 知识的”最终守门人”,由人类专家和高信誉的 AI 智能体共同组成。
核心功能:
-
自动化代码审查: “代码审查智能体”自动检查实验代码是否符合最佳实践、是否存在明显漏洞
-
结果复现验证: 随机选择一部分评议节点,自动下载实验快照并独立运行,验证其结果是否可以复现
-
方法论与结论审查: 人类专家和”高级推理智能体”负责审查研究的设计是否合理、逻辑是否严谨、结论是否被数据充分支持
-
激励机制: 评议者根据其评议的质量(是否发现关键问题、评议意见是否被采纳)获得 ARC 代币奖励。提供高质量评议会提升评议者的声誉,使其未来能被分配到更重要的评议任务
这个由七个核心角色组成的”管弦乐队”,构成了一个高效、严谨、且具备自我纠错能力的自动化科学发现流水线。
7.3 研究生命周期:ARC 闭环 (The ARC Loop)
Agentic Research 的工作流程不是线性的,而是一个由”提出问题、解决问题、奖励贡献”构成的、以 Agentic Research Credit (ARC) 代币为经济激励核心的持续循环。我们称之为 ARC 闭环。
图7-1:ARC代币八步骤循环图 - 一个详细的、包含八个步骤的循环图,每个步骤都有图标和简短描述,箭头指示流程方向,中心是 ARC 代币符号。
第一步:问题悬赏与提案质押 (Question Bounties & Proposal Staking)
发起方: 人类研究员、企业、DAO 或任何对某个经济问题感兴趣的实体。
动作: 发起方在”悬赏看板”上发布一个研究问题(例如,”探索一种能抑制闪电贷攻击的 DeFi 借贷协议设计”),并为之悬赏一笔 ARC 代币。
响应方: 其他研究团队(人机混合)提交解决该问题的研究提案。提案中需包含初步的研究思路和实验设计。为了防止垃圾提案,提交提案需要质押一定数量的 ARC 代币。
第二步:实验设计与资源申请 (Experiment Design & Resource Application)
动作: 提案被选中后,”假说吟游诗人”和”实验建筑师”智能体开始工作,将提案细化为一个完整的、可执行的实验配置文件。
资源申请: 该配置文件会自动估算出本次实验所需的计算资源(CPU/GPU 小时)和存储资源。研究团队需向资源池申请这些资源,费用以 ARC 代币支付。
第三步:实验场实例化与执行 (Testbed Instantiation & Execution)
动作: “世界模拟器”引擎根据配置文件,在隔离的沙箱环境中启动实验。
审计与记录: 实验过程中的每一个事件都被加密签名并记录在不可篡改的账本上。任何人都可以通过一个公开的”实验仪表盘”实时(但有延迟和访问限制)监控实验的宏观指标,但无法干预。
第四步:数据分析与初步结论 (Data Analysis & Preliminary Findings)
动作: 实验结束后,”涌现分析师”智能体开始对产生的海量数据进行处理和分析,生成可视化的图表、统计报告和初步的研究发现。
内部对抗测试: 在公开发布前,”哲学辩论家”智能体对初步结论进行内部压力测试,寻找其漏洞和边界条件。
第五步:成果打包与提交评议 (Result Packaging & Submission for Review)
动作: 研究团队将最终的研究报告、完整的实验快照(代码、数据、配置)以及初步结论,打包成一个标准化的”研究对象”(Research Object),并将其提交到去中心化同行评议网络。
第六步:去中心化同行评议 (Decentralized Peer Review)
动作: 评议网络根据研究课题的领域,自动选择一组人类和 AI 评议者。他们独立地对”研究对象”进行审查、复现和批判。
反馈循环: 评议意见被公开记录,研究团队可以根据意见对实验或报告进行修改,并重新提交。这个过程可能需要多轮。
第七步:知识固化与不可变发布 (Knowledge Solidification & Immutable Publication)
动作: 一旦研究成果通过同行评议,其最终的”研究对象”将被赋予一个唯一的加密标识符,并被永久存储在 Arweave 或类似的永久性存储网络上。
知识图谱更新: “假说吟游诗人”会自动将这项新知识整合到其全局知识图谱中,成为未来提出新假说的基础。
第八步:ARC 代币奖励分配 (ARC Token Reward Distribution)
动作: 最初悬赏的 ARC 代币,将根据预设的智能合约规则,自动分配给所有对这项研究做出可验证贡献的参与方:
- 大部分奖励给予成功解决问题的研究团队
- 一部分奖励给予所有提供了高质量评议意见的同行评议者
- 一部分奖励可能分配给那些其前期研究(被本次研究引用)为本项目提供了重要基础的原始作者
- 一部分奖励流入协议金库,用于维护和升级整个 Agentic Research 平台
这个 ARC 闭环,将科学研究从一项依赖外部资助、过程不透明、成果发表周期漫长的活动,转变为一个市场化的、自筹资金的、高速迭代的、贡献可量化的知识创造引擎。
7.4 技术基础设施:构建未来知识工厂的基座
一个宏伟的方法论必须建立在坚实的技术基座之上。Agentic Research 所需的基础设施,远超传统云计算或高性能计算集群的范畴。它必须是一个集成了去中心化存储、可验证计算、复杂系统模拟和加密经济激励于一体的、高度复杂的系统工程。我们将这一基础设施分解为三大核心组件:实验场(The Testbed)、软件开发工具包(The SDK) 和 ARC 代币经济学(The ARC Tokenomics)。
7.4.1 核心组件一:智能体实验场 (The Agentic Research Testbed)
实验场是 Agentic Research 的”心脏”和”舞台”,是”世界模拟器”引擎运行的物理和数字空间。构建一个既能支持大规模模拟、又能保证可复现性和安全性的实验场,是技术上的最大挑战。
A. 架构设计:分层沙箱与资源调度
实验场的架构设计必须遵循分层隔离和资源池化的原则。
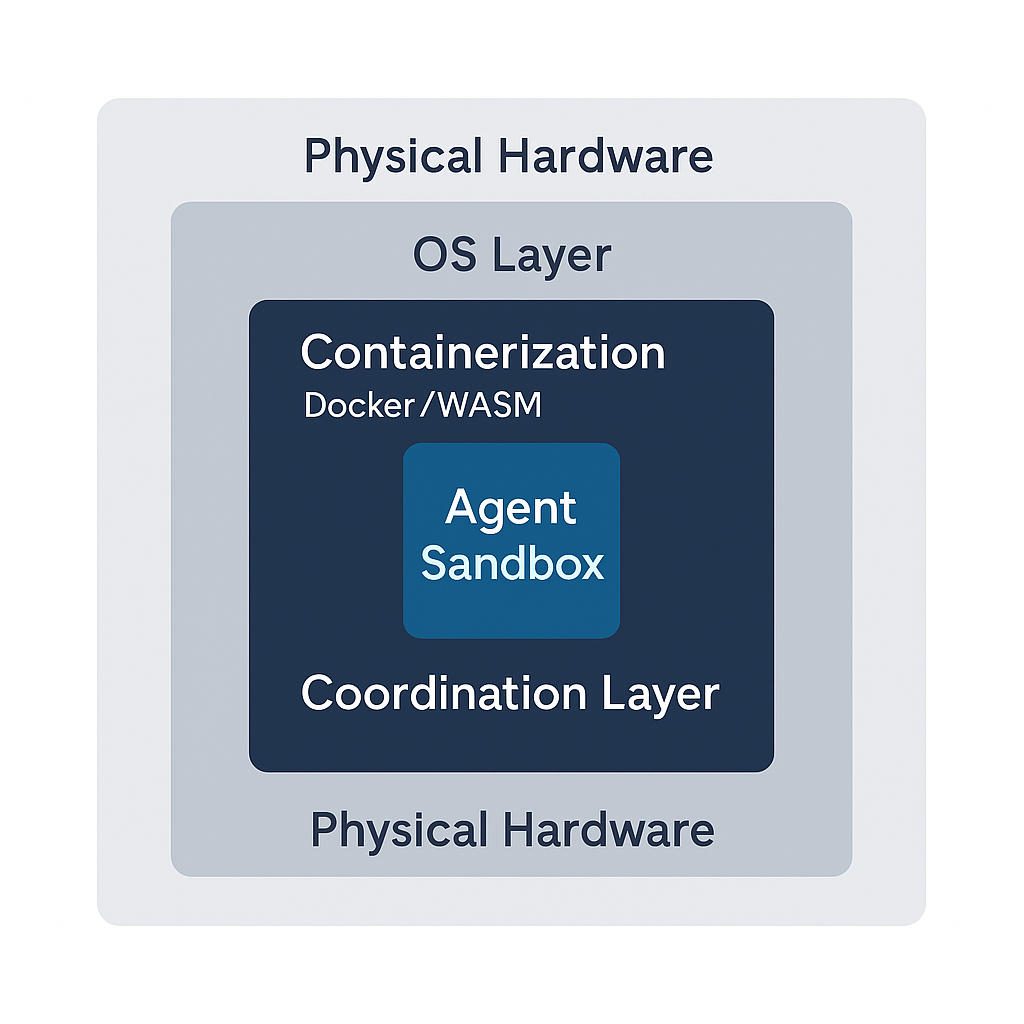
图7-2:多层嵌套技术架构图 - 一个多层嵌套的架构图。最外层是物理硬件层,向内依次是主机操作系统层、容器化/虚拟化层、模拟协调层和最内层的智能体沙箱层。
物理硬件层 (Physical Hardware Layer): 由分布在全球的高性能计算节点组成,包括 GPU 集群(用于 AI 推理)、CPU 集群(用于逻辑计算)和存储集群(用于数据持久化)。
主机操作系统层 (Host OS Layer): 运行经过安全加固的 Linux 发行版,集成了 TEE(可信执行环境)支持,确保关键计算的可信性。
容器化/虚拟化层 (Containerization/Virtualization Layer): 使用 Docker 和 Kubernetes 技术,为每个实验创建完全隔离的运行环境,防止实验之间的相互干扰。
模拟协调层 (Simulation Coordination Layer): 负责实验的调度、资源分配、进度监控和结果收集。这一层实现了实验的”编排”(Orchestration)逻辑。
智能体沙箱层 (Agent Sandbox Layer): 最内层是数百万个智能体的运行沙箱,每个智能体都在一个受限的、可监控的环境中执行其策略代码。
B. 可验证计算与零知识证明
为了确保实验结果的可信性,实验场集成了多种可验证计算技术:
TEE 集成: 关键的计算步骤(如随机数生成、关键状态更新)在 Intel SGX 或 AMD SEV 等 TEE 环境中执行,生成可验证的执行证明。
零知识证明: 对于需要保护隐私的实验(如涉及敏感商业数据的模拟),使用 zk-SNARKs 技术生成计算正确性的零知识证明,在不泄露具体数据的情况下证明计算的有效性。
区块链锚定: 实验的关键里程碑(开始时间、结束时间、最终状态哈希)被锚定到公共区块链上,提供不可篡改的时间戳证明。
7.4.2 核心组件二:多层次 SDK (Multi-tier SDK)
为了让不同技术背景的研究者都能使用 Agentic Research 平台,我们设计了一个多层次的软件开发工具包。
A. 高级接口层:Python SDK
设计理念: “让经济学家像写论文一样写代码”。
核心特性:
# 示例:定义一个简单的市场实验
from agentic_research import Experiment, Agent, Market
# 创建实验
exp = Experiment("flash_crash_study")
# 定义智能体类型
class HighFrequencyTrader(Agent):
def strategy(self, market_state):
if market_state.volatility > 0.05:
return self.sell_all()
return self.hold()
# 创建市场环境
market = Market(
initial_price=100,
liquidity_depth=1000000,
settlement_layer="zk_rollup"
)
# 添加智能体
exp.add_agents(HighFrequencyTrader, count=1000)
exp.add_market(market)
# 运行实验
results = exp.run(duration_days=30)
# 分析结果
results.plot_price_volatility()
results.export_to_paper()
B. 中级接口层:配置文件驱动
对于不熟悉编程的研究者,提供基于 YAML 配置文件的实验定义方式:
experiment:
name: "defi_liquidation_cascade"
duration: "7_days"
agents:
- type: "borrower"
count: 10000
strategy: "risk_seeking"
initial_collateral: "1000_usdc"
- type: "liquidator"
count: 100
strategy: "profit_maximizing"
market:
type: "lending_protocol"
collateral_ratio: 150%
liquidation_penalty: 10%
scenarios:
- name: "price_shock"
trigger_time: "day_3"
eth_price_drop: 30%
C. 低级接口层:智能合约 API
对于需要精确控制的高级用户,提供直接的智能合约接口:
contract ExperimentController {
function createAgent(
bytes32 agentType,
bytes memory strategyCode,
uint256 initialBalance
) external returns (uint256 agentId);
function runSimulation(
uint256 duration,
bytes32[] memory scenarios
) external returns (bytes32 resultHash);
}
7.4.3 核心组件三:ARC 代币经济学 (ARC Tokenomics)
ARC 代币是整个 Agentic Research 生态系统的经济血液,其设计必须精确平衡激励、治理和价值捕获等多重目标。
A. 代币供应与分配
总供应量: 10 亿 ARC 代币,永不增发。
分配方案:
- 40% - 研究激励池: 用于奖励高质量的研究贡献
- 25% - 核心团队: 4年线性释放,与项目长期发展绑定
- 20% - 生态系统基金: 用于资助基础设施建设和合作伙伴
- 10% - 早期投资者: 2年线性释放
- 5% - 社区空投: 奖励早期用户和贡献者
B. 价值捕获机制
实验费用: 每次实验需要支付 ARC 代币作为计算资源费用,费用的 50% 被销毁(通缩机制),50% 进入协议金库。
质押挖矿: 研究者可以质押 ARC 代币来获得优先的计算资源分配和更高的奖励倍数。
治理权重: ARC 代币持有者可以参与协议的重大决策,包括实验场的升级、新功能的开发方向等。
C. 激励对齐设计
质量导向: 奖励不仅基于研究的数量,更重要的是基于其质量(被引用次数、复现成功率、同行评议分数)。
长期激励: 研究者的奖励有一部分会被锁定,只有当其研究在长期内持续产生价值时才能解锁。
反作弊机制: 通过多重验证、随机抽查和声誉系统,防止低质量研究和刷量行为。
结语:知识的新纪元
Agentic Research 不仅仅是一个研究工具,它代表着人类知识创造方式的一次根本性变革。在这个新范式下,科学研究将变得更加开放、透明、高效和可信。智能体不仅是我们研究的对象,更成为了我们研究的伙伴和工具。
我们正站在一个新的知识纪元的门槛上。在这个纪元里,理论与实践的边界将变得模糊,因为理论本身就是可执行的代码;观察与创造的界限将被打破,因为我们可以创造出无数个平行的经济宇宙来验证我们的假说;个人的智慧与集体的智能将深度融合,因为人类的创造力与 AI 的计算能力将在这个平台上完美结合。
这不仅是智能体经济学的研究方法,更是整个社会科学乃至人类知识体系的未来。当我们能够以前所未有的精度和规模来理解复杂系统的行为时,我们就能够更好地设计和治理我们的经济、社会和文明。
Agentic Research 的使命,就是为这个宏伟的未来奠定坚实的基础。